开发者可以怎样降低以太坊Layer2上的交易费用
自 2020 年以来,Ethereum 的扩张路线图一直围绕「Rollup」展开: 使用证明(无论是零知识证明还是 optimistic 欺诈证明)来继承 Ethereum 安全性的独立执行环境。
经过多年的发展,Rollup 终于完成了部署,并正在获得采用。Arbitrum 的王牌 optimistic Rollup 已经上线近一年,期间有价值超过 27 亿美元的资产存入跨链桥,而 Optimism 则紧随其后。Loopring 和 dydX 等针对于特定应用程序的零知识 Rollup 也得到了广泛使用,许多竞争性的通用零知识 Rollup 将在未来几个月内推出。
尽管 Rollup 如今正在快速迅速,但一些人还是担心其费用居高难下。

事实上,Arbitrum 和 Optimism 的交易费用仍然显著高于 Solana 和 Polygon 等「低费用」链。
那么,是什么阻碍了这些 Rollup 的发展?
Rollup 经济学
为了理解交易费用,我们首先需要分清区块链交易所产生的各种成本:
・执行
这是一个网络中所有节点执行交易并验证结果是否有效所需的成本(例如:你实际拥有你所转移 Token 的所有权)。
・存储/状态
这是用新值更新区块链「数据库」的成本(例如:在 Token 转移后,发送方的余额减少,接收方的余额增加)。
・数据可用性
为了让区块链保持去信任化并可被所有人验证,区块链必须确保所有关于交易的相关数据与所有网络参与者公开共享。从本质上讲,这就是要保证世界上每个人都能看到你的交易。如果没有这种保证,各种攻击就都有可能发生(被称为扣块攻击)。
正如我们所见,数据可用性是当今区块链的关键瓶颈之一。
Rollup :将执行转移至链外
Rollup 的主要进步在于,它将区块链的执行和存储转移到了「链外」,即一组有限的节点上进行。与其让网络中的每个 Ethereum 节点执行所有交易或存储每条更新,我们可以直接把这个任务委托给 Rollup 运营商。
不过,这是否意味着我们需要信任这群操作员?难道这不是中心化吗?
Rollup 会使用各种证明类型来继承 Ethereum 的安全性。Optimistic Rollup 允许单一诚实的实体提交一个「欺诈证明」,并为一个行为不端的序列器赢得奖励,而 ZK Rollup 使用零知识证明来证明 Layer-2 链已经正确更新。
数据可用性的权衡
将执行从主链转移可以大大降低执行和状态存储的成本,不过 Rollup 仍需要将他们的数据发布到 Layer-1 链上以确保数据的可用性。从本质上讲,Rollup 支付低廉的 Layer-2 执行和存储成本,但仍需要支付 Layer-1 的费用来发布他们的数据。
这可以在 ArbiScan 区块浏览器中任何交易的「Advanced TxInfo」标签上看到。交易费用由发布到 L1 的调用数据成本、L2 上使用的计算和 L2 存储构成,而在几乎所有的交易中,L1 的调用数据都是费用的主要来源。也就是说,Rollup 上最需要解决的问题便是将数据发布到 Layer-1 的费用问题。
数据可用性的未来
虽然数据可用性对于 Rollup 来说仍是一大瓶颈,但随着时间推移这种情况也会得到缓解。
Ethereum 的升级,如 Proto-Danksharding 和最终的完全 Danksharding 将大大降低向 Ethereum 发布数据的成本。此外,Celestia 这样的项目旨在提供独立的链,而这些链是专门为提供廉价的数据可用性而建立的。
从长远来看,Danksharding 和 Celestia 这样的系统将降低数据可用性成本并增加其丰富性,同时将问题抛回到执行层面。然而,这些解决方案还需要时间才能完全成熟:Celestia 还有几个月的时间才会发布其主网,而在 Ethereum 能够增加像 Proto-Danksharding 这样的数据可用性升级之前,可能还需要一年多的时间。
调用数据压缩
数据压缩是一个比计算机本身还要古老的领域。莫尔斯电码发明于 1838 年,是已知最早应用数据压缩的实例。然后,计算机的使用加速了人们对于数据压缩的研究,于是上世纪 50 年代哈夫曼编码这样的算法就发明了出来。
鉴于 Rollup 的执行成本低廉,但数据可用性成本昂贵,这些团队一直在将数据压缩算法整合到他们的协议当中。Optimism 已经将 Zlib 压缩算法整合到他们的 Rollup 中,而 Arbitrum 即将推出的 Nitro 升级版则使用了 brotli 压缩算法。
注意:这个实验可能是在 Nitro 发布之前仓促完成的,以便在未压缩的 Arbitrum 调用数据上进行实验。
数据压缩算法肯定是有用的工具,有助于降低这些调用数据的成本。然而,压缩区块链交易是一项艰巨的任务:数据压缩的作用是寻找相同的模式并缩短它们。然而,交易中充满了地址、哈希值和签名,对于这些压缩算法来说,它们本质上是「随机数据」,不具有相似性。
只有当开发者开始关心如何减少他们应用程序中的调用数据,该类数据的成本才能真正降低。2020-2021 年的天价 Gas 价格迫使开发者优化他们的代码,以尽量减少执行和状态存储。

当我们过渡到 L2 世界时,调用数据将从最便宜的资源变成最昂贵的资源,因此开发者必须再次学习这些新的优化方案。
实验:我们可以将一次简单的 Token 传输压缩到什么程度
现在让我们在 Arbitrum 上做一个实验:我们可以将一个简单的 Token 传输所需的调用数据压缩到什么程度?这些优化能在多大程度上降低交易费用?
实验设计与控制组交易
为了进行我们的实验,我们将建立一个简单的智能合约,将一个 Token 从交易发送方转移到任何给定的地址。
这个智能合约确实需要用户在发送我们的实际测试交易之前,先发送一个 approve() 交易。由于这个限制,用户可能不会想用这个系统进行 Token 转移。然而,本实验中用到的节约成本方法也可以应用于其他合约(例如,优化的 Uniswap 路由器)。
在实验开始时,我们将发送一个「控制」交易以获得基准成本,它会调用一个简单的 Solidity 函数,用于传递 Token 地址、接收者地址和要转移的 Token 数量。
我们的测试交易使用了 576,051 个 ArbiGas,总费用为 0.43 美元。

数据删减
用于对照组的调用数据有很多我们可以剥离出来的不必要数据。首先,我们需要删除所有的零,这些零只是用于数据填充。虽然它们非零字节更便宜,但仍会产生成本,所以我们需要将其删除。
开头还有一个 4 字节的函数签名,它是我们试图调用哪个 Solidity 函数的标识符。我们可以删除这个数据,让我们的代码推断出我们所要采取的行动。
经过这两步优化之后我们已经将字节码从 100 减少到 43 了。这样一来,我们的测试交易使用了 494,485 ArbiGas(减少了 14%),花费 0.37 美元。

「助手」合约
现在我们的大部分数据是由调用数据中的两个地址组成的:一个是我们要转移的 Token 地址,另一个是转移的接收地址。
然而,我们可以假设大多数用户都在转移同样的几种 Token(WETH,Dai,USDC)。所以,从调用数据中删除整个 Token 地址的其中一个方法是为该 Token 部署一个特殊的「助手」合约。如果我们可以把交易发送给这个助手,就完全避免了发送 Token 地址的必要。
这样我们就把数据字节码减少到了 23 字节,测试交易使用了 457,546 ArbiGas(比对照组减少了 21%),成本为 0.34 美元。

地址查询表
上一阶段我们用「助手合约」从调用数据中删除了一个地址,但是我们的调用数据中仍包含有另一个地址。
我们是否可以可以找到另一种更可靠的「压缩」地址方法呢?
值得庆幸的是,Arbitrum 有一个名叫「地址表注册」的内置合约,我们可以用它来缩短我们的调用数据。
这个合约本质上是一个「电话簿」,可以将 20 字节的 Ethereum 地址转换为简单的整数。想象一下,你的朋友有一本传统的电话簿:与其把你的整个电话号码读给他们听,不如直接说「我是电话簿第 200 页上的第 4 个电话号码」,然后让他们查到你的号码。
因此,我们可以制定一个合约并用「地址索引」来代替完整的地址,并在内部查询到它。
这样我们既省去了 Token 地址又省去了接收地址,从而将将调用数据减少到 9 字节。如此一来,我们的测试交易使用了 428,347 ArbiGas(比对照组减少了 26%),成本为 0.32 美元。

方法合并
最后,让我们把所有的方法整合到一起:
・移除数据填充与函数选择器
・使用辅助合约来删除常见的地址
・使用 Arbitrum 地址表来缩短其他地址
全部加在一起,我们的调用数据大小现在只有 6 个字节了。最后的测试交易使用了 426,529 ArbiGas(也比对照组减少了 26%,比之前的测试组略低),花费 0.32 美元。


有损压缩
我们刚刚谈到的所有压缩方法都属于「无损压缩」,即压缩后的输出包含与原始输入相同的所有数据。
但就像照片和视频文件通常会使用「有损压缩」算法来删除不必要的信息一样,我们也可以在大多数情况下删除不必要的数据。
我们可以通过缩短数字来去除不必要的精度。例如,ERC-20 Token 往往有着 18 位小数的精度,但大多数用户通常只关心小数点后 4 位。为此,我们可以建立一个合约,默认接受小数点后 8 位的数字并乘以 10 的 10 次方,并为需要更多精度的用户提供相应的辅助功能。
同样,日期通常表示为「1970 年 1 月 1 日以来的秒数」(也被称为 Unix 时间)。合约可以通过设定的不同的时间单位,如分钟、小时或天来减少这个整数的大小,并可以设置自己的「纪元」,例如,2015 年 1 月 1 日。
经验总结
总之,调用数据已经从 Ethereum L1 上最便宜的资源,变成了 Ethereum Rollup 上最昂贵的资源。Proto-Danksharding 和 Celestia 这样的数据可用性技术最终会解决这一问题,但二者都还没有上线,而且数据可用性变得廉价且普遍可能还需要几年时间。
因此,区块链开发者需要非常注意他们交易所需的调用数据数量,因为这对终端用户的交易费用会产生重大影响。
这篇文章概述了一些可用于减少调用数据的技术方法,我相信随着越来越多的「优化大军」将注意力转向 Layer 2,此类方法将变得愈发丰富。
原文标题:《Crunching the Calldata》
原文作者:David Mihal
原文编译:Kxp,BlockBeats
来源:区块律动
[注:本文部分图片来自互联网!未经授权,不得转载!每天跟着我们读更多的书]
互推传媒文章转载自第三方或本站原创生产,如需转载,请联系版权方授权,如有内容如侵犯了你的权益,请联系我们进行删除!
如若转载,请注明出处:http://www.hfwlcm.com/info/158491.html
相关文章
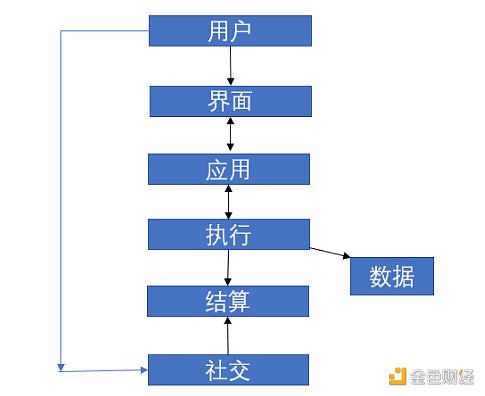
Web3 堆栈:web3 如何提供比 web2 更好的用户体验?
许多 web3怀疑者在使用web3相关产品之后很快就批评说用户体验很糟糕,即使是 web3的拥护者也经常承认用户体验可能没有那么好,但去中心化带来的良好特性能弥补这个缺陷。 事实证明...
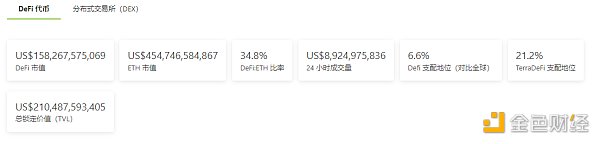
金色Web3.0 | 中国证券报:当下很多娱乐明星在积极入
DeFi数据 1.DeFi代币总市值:1582.26亿美元 DeFi总市值 数据来源:Coingecko 2.过去24小时去中心化交易所的交易量:41.0亿美元 过去24小时去中心化交易所的交易量 数据来源:Coingecko 3.DeFi中锁定...

透过数据回顾 2021 跟随趋势展望 2022
2021年NFT市场概况 到目前为止,Ethereum上NFT销售额在 2021 年已超过 90 亿美元,比 2020 年的总销售额增长了 2500%。2021 年作为NFT元年,同时出现在牛市周期的背景下,NFT市场的规模呈现惊人...

MRFR报告称Web 3.0市场到2030年呈指数增长
研究机构 Market Research Future (MRFR) 的综合研究报告指出,Web 3.0 区块链的市场规模到 2030 年将以健康的复合年增长率增长。Web 3.0 区块链技术是市场上的最新热点。考虑到未来的互联网,...

Michael Clare:数据安全防卫是ADAMoracle战略阵地
在过去的一年,由于加密市场的火热,和各个项目的激烈角逐,这样高速的发展不仅使加密货币总市值刷新了历史新高,同样也带来了安全隐患,行业内安全事件频发,黑客盗币的金额...

金融科技年度十大技术趋势:隐私计算区块链都是重
金融科技圈的技术走向该如何看? 今天,北大光华-度小满金融科技实验室发布了「2022全球金融科技十大技术趋势」,涵盖隐私计算、大模型、多模态学习、数字孪生等多个前沿领域。...

引领未来·2022全球Web3.0高峰论坛精彩内容回顾
2021年12月30日,由NirvanaMeta主办,DCG、Foundry、Animoca、a16z、Grayscale、Coindesk、Genesis、LUNO、OFFChain、BalletCrypto及OASIS实验室作联合主办单位,VPM公会、AG Crypto Investment、虫...
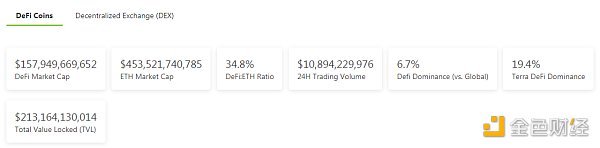
金色Web3.0日报 | “变异猿”MAYC交易总额突破6亿美元
DeFi数据 1.DeFi代币总市值:1579.49亿美元 DeFi总市值 数据来源:Coingecko 2.过去24小时去中心化交易所的交易量:56.31亿美元 过去24小时去中心化交易所的交易量 数据来源:Coingecko 3.DeFi中锁...