GeForce RTX 4070天梯榜首发评测:一张更加主流的2K游戏显卡
1月初的时候,NVIDIA推出了RTX 4070 Ti,时隔3个月之后,他们又带来了同样基于AD104核心的,参数和定价上更为主流的RTX 4070。结合最近的笔记本市场,可以说NVIDIA正在稳步推进Ada Lovelace GPU的全方位布局。我们这次所评测的显卡,是NVIDIA GeForce RTX 4070 Founder Edition,也就是大家爱称的公版显卡。

一直以来,60和70两个后缀的显卡都是相当受玩家欢迎的,毕竟它们在符合预算的前提下,各方面的表现都不错,特别像70后缀的卡,更是老而弥坚,可以在相当长一段时间内确保游戏的流畅运行。因此,对于新的RTX 4070来说,它面临的挑战其实并不小,除了吸引新玩家外,让持有前代70后缀显卡的玩家动心也是相当重要的一个任务目标。
RTX 4070系列显卡规格


RTX 4070所采用的AD104核心共启用了5888个CUDA核心,184个第四代Tensor Core和46个第三代RT Core,整体规模比RTX 4070 Ti少了约23%。而显存方面,它的配置和RTX 4070 Ti是一致的,均为12GB GDDR6X显存,带宽为192bit。至于功耗这块,RTX 4070的TGP仅为200W,比起上一代来说可是低了不少,也就是RTX 3060 Ti的水平。虽说NVIDIA官方的推荐是选用650W的电源,但事实上更低一点也是没什么问题的。
Ada Lovelace架构解析 SM架构图

到了SM单元里面,会发现其整体的结构也是与上一代Ampere架构一模一样,分为四个一样的主要计算模块,一个RT光追核心,以及128KB一级数据缓存/共享内存等。每个主要的计算模块内的结构也和Ampere架构一样,有64KB寄存器文件、零级指令缓存、一个Warp调度器、一个分配单元、16个FP32单精度浮点CUDA核心、16个FP32/INT32单精度浮点和整数混合CUDA核心、一个Tensor Core张量核心、四个载入存储单元、一个特殊功能单元(SFU)用于执行图形差值指令。
差别也很明显,那就是RT Core光追核心从之前的第二代升级到第三代,Tensor Core张量核心也从第三代升级到第四代。
第三代RT Core有效光追算力是上代3倍


全新的第三代RT Core可以提供2倍的光线与三角形求交性能,并且加入了两个全新的重要硬件单元,即Opacity Micro-Map引擎和Displaced Micro-Mesh引擎。
Opacity Micro-Map引擎将光线追踪的Alpha-Test几何性能提升2倍;而全新的Displaced Micro-Mesh引擎可动态生成微网格,以产生额外的几何图形。Displaced Micro-Mesh引擎可在提升几何图形丰富度的同时,不以传统复杂几何图形处理的性能和存储成本为代价。
Displaced Micro-Mesh引擎

光线追踪的计算是以光线射向一个平面这样的模型来计算的,而实际的渲染中物体几乎不会是简单的平面型,而是各种曲面,所以就需要将曲面分解成许多个小的三角形平面,然后计算光线与三角形求交。在Ampere架构上,面对一个复杂的曲面,如果想得到逼真的光线追踪效果,那么分解的三角形平面是非常多的,多个三角形平面带来非常复杂的BVH,这就非常难以计算。

Ada Lovelace架构的处理方式就不一样,通过Displaced Micro-Mesh引擎,它将这些三角形平面仅通过一个三角形然后加上不同的位移图来表达,显著缩短了BVH的构建时间,同时BVH的存储空间需求也减小了很多,而最终仍然能实现一样的光线追踪最终渲染效果。

实际应用中由于Displaced Micro-Mesh引擎的存在,面对复杂物体的渲染,BVH的构建速度可以超过15倍,而存储空间的需求却可以小20倍之多,越是复杂的物体该引擎的优势就越能体现。

而且Displaced Micro-Mesh引擎不止可以应用在游戏领域,对于创作领域的用户来说,也有软件会支持,目前Adobe、Simplygon这两家企业已经确认得到了支持。
Opacity Micro-Map引擎

Opacity Micro-Map引擎则是可以对游戏中常见的树叶这类物体加速光线追踪计算,Ampere架构面对这种场景的Alpha-Test需要多个着色器来进行计算,而Opacity Micro-Map引擎对于这种不透明的对象进行了不透明度的编码,可以更准确的对物体边缘进行光线追踪计算,简化了叶子轮廓之外完全透明和叶子轮廓之内完全不透明的区域的计算,耗费更少的着色器就可以实现真实的光线追踪渲染。

以《传送门》RTX版这个游戏为例,Opacity Micro-Map引擎可以让Gbuffer填充速度加快30%,游戏帧率提高10%。
在这些改进下,第三代RT Core可以使完整的Ada Lovelace架构核心具有200 TFLOPS的有效光线追踪计算能力,几乎是上代产品的三倍。
第四代Tensor核心性能超上代5倍

第四代Tensor Core最主要的变化是新增了Hopper FP8 Transformer Engine,可提供1400 TFLOPS的张量处理性能,可以说深度学习性能得到了巨大的飞跃,这也意味着通过它可以实现新的技术想法,后面的DLSS 3我们会再次提到Tensor Core的功劳。
DLSS 3作为这次NVIDIA大力宣传的重点,相信大家都急不可耐想深入的了解这个技术,但是为了更清楚的了解DLSS 3,还要先介绍两个新东西,那就是着色器执行重排序(SER)和Optical Flow Accelerator光流加速器。
着色器执行重排序(SER)提高光追并行效率

着色器执行重排序技术的重大作用是可以极大的提升光线追踪性能,这是与CPU的乱序执行一样的重大创新。
由于光线追踪的特性,它很难并行处理,因为光线会向各个方向反射,并与各种类型的表面相交,所以光线追踪的工作负载需要不同的线程处理,需要不同的着色器,并且需要不同的显存来存取中间的计算过程。

GPU的特点就是适合并行处理,只有面对并行处理的任务才可以发挥GPU的特点获得更好的计算效率,而着色器执行重排序就是可以通过实时重新调度任务,即时重新安排着色器负载来提高执行效率,从而更好地利用GPU资源,以实现更佳的光线追踪性能,据称,SER可以为光线追踪带来最高可达3倍的性能提升,整体游戏性能提升可高达25%。

应用了着色器执行重排序(SER)之后,《赛博朋克2077》在全景光线追踪模式下可以提高44%的性能,《传送门》RTX版可以提高29%的性能,《Racer RTX》可以提高20%的性能。
Ada光流加速器算力可超300 TFLOPS
回看前面的完整核心图,可以看到左上角清晰的标出了Optical Flow Accelerator,也就是光流加速器,而尽管之前的Ampere架构中没有提及,但同样也是具备的。不同的是,Ada Lovelace架构中大大增加了光流加速器的运算性能,从之前Ampere架构的126 TFLOPS增加到现在的300 TFLOPS(详细值是305 TFLOPS)。
Ada的光流加速器带来的巨大的性能提升,具有更广泛的实用性了,使DLSS 3能够更准确预测场景中的运动,使神经网络能够在保持图像质量的同时提高帧率。前面提到的第四代Tensor Core的1400 TFLOPS的张量处理性能,加上这里Ada Lovelace光流加速器300 TFLOPS的光流运算性能,再加上后方的NVIDIA超级计算机提供的超过1 ExaFLOPS的AI计算性能,这三者就组成了这一代DLSS 3的硬件层面基础。
DLSS 3全方位提升流畅度、延迟和画质

新一代的DLSS 3包括全新的帧生成技术、DLSS 2超分辨率技术和NVIDIA Reflex技术,与之对应的游戏中,这三个都启用了才算是完整地开启了DLSS 3。
其中帧生成必须RTX 40系列GPU才能支持,超分辨率则是RTX 40/30/20系列都支持,Reflex的要求最低是GTX 900系列及以后的GPU。总得来说,DLSS 3是提升游戏体验的一整套解决方案,也就是说对于游戏体验的三要素:流畅度、延迟和画质。DLSS 3是全方位的提升,而不是以拆东墙补西墙的方式。

DLSS 3的帧率

之前的DLSS 2,提升帧率的方式简单说就是以低分辨率渲染,然后通过AI训练重建高分辨率画面返回输出,比如我们将游戏设置成4K,打开DLSS,那么实际的计算过程是先以1080p分辨率渲染帧画面,然后AI学习经过训练的更高分辨率的帧再将这个帧画面压缩到4K最终输出,中间相差的这3/4部分的像素信息是通过AI计算来添加的(本地主要是Tensor Core来计算)。由于以低分辨率渲染,所以在AI补充像素的性能足够的情况下,帧率自然可以提高了。
这样的方式无法突破CPU性能的瓶颈,毕竟降低原始渲染分辨率可以使得GPU每一帧的计算量更少,但是CPU每一帧的计算量是不变化的(因为CPU负责计算的部分与分辨率并无关系)。实际上,由于帧率提高,最终CPU的计算量还增大了。
那么DLSS 3是怎么做的呢?

首先,还是与DLSS 2一样,比如输出4K游戏画面的话,它也是先降低原始渲染分辨率到1080p,然后通过AI计算来添加像素再压缩成4K画面。在连续的游戏画面中,我们就可以通过这样得到连续的4K帧画面,第1帧、第2帧、第3帧等等。

然后这样的每两帧之间,DLSS 3通过光流加速器为神经网络提供像素级的帧到帧的运动方向和速度信息,然后通过分析前一帧和当前帧几何图形和像素的运动矢量并将其输入至神经网络,就能计算出两帧中间的帧画面了。
实现超越CPU限制的帧数

这样连续下去的话,原本的第1帧、第2帧、第3帧中间都会有一个新的帧,等于实际最终输出的帧画面中,有1/2是没有CPU参与的,完全是GPU计算出来的,所以理论上可以将原本受限于CPU性能的游戏帧率提高一倍。

另外,我们去关注像素的话,会发现靠传统渲染方式计算的像素其实只有1/8,最终输出的游戏画面7/8的像素其实都是通过DLSS 3的一系列AI计算填补上的,这极大的提升了效率。
DLSS 3的画质

其实看我们的网站的网友评论可以看到,还是有很多网友对DLSS技术很抗拒,认为不是原始渲染出的画面就不好,或许这一观念是时候需要改变了。且不说网友有这一观念可能是由于初代DLSS技术确实效果不佳,形成了刻板印象,即便之后的DLSS 2超分辨率技术已经有很好的画面也很难摒弃已经形成的观念,对于现在的DLSS技术其实可以比较一下这几帧画面,已经完全看不出区别。

对于DLSS 3的生成帧这方面大家不免想到已经问世好久的各种插帧技术,DLSS 3的生成帧确实也可以算作插帧的一种,但是又与其他的插帧技术完全不一样。

简单的插帧技术利用两帧之间像素的位移来确定中间帧的图像,这样其实非常容易出现明显令人觉得视觉异常的画面,特别是对于阴影这种需要计算的画面效果,当主体移动之后,正确的阴影是需要经过复杂计算的,单单根据像素的位移来确定的画面几乎肯定违反客观世界的物理规律。

DLSS 3使用光流加速器分析两帧连续的游戏图像,计算帧到帧之间物体、元素的运动矢量数据,综合游戏中的一对超级分辨率帧,以及引擎和光流运动矢量,并将其输入至卷积神经网络,计算生成出新的一帧,大大提高了画面的准确性。
DLSS 3的延迟

通过前面的梳理大家会发现DLSS 3尽管提高了帧速率,也保证了画质,但是对于延迟是没有缩短的,因为每一个新生成的帧都是需要后一帧渲染出来之后才可以准确生成的。更高的帧率提升了游戏的顺滑程度,但延迟会影响游戏的响应度,如果延迟太高,游戏的体验也不会好,而为此,DLSS 3也集成了NVIDIA Reflex技术来降低延迟提高响应速度。

总得来说,DLSS 3是包括了基于AI的超分辨率提升技术、基于AI的帧生成技术以及NVIDIA Reflex低延迟技术这些软件层面以及第四代Tensor Core的1400 TFLOPS的张量处理性能、Ada Lovelace光流加速器300 TFLOPS的光流运算性能以及NVIDIA超级计算机提供的超过1 ExaFLOPS的AI计算性能组成的硬件层面综合实现的一项新技术,对于游戏体验的提升也不是单方面的,而是全方位的提升。
外观:足够小巧的一张显卡
从我们之前的评测可以知道,这次RTX 40系列FE显卡的设计语言大体上继承自30系列。RTX 4070也不外乎是这样,但是RTX 4070这次也采用了双轴流推挽式风扇散热设计,这和上一代有很大的不同:RTX 3070仍然是正面双轴流风扇的设计,到了RTX 3070 Ti才是正反各一把风扇。

RTX 4070这次的外观设计其实更像是RTX 4090/4080 FE系列的迷你版,比如说银色的无限符号状的铝制外框,还有正面右侧的鳍片,也是呈箭头状向左指向风扇处。两个风扇均为7片扇叶设计,直径为90mm。虽然比起前两张FE显卡,这两把风扇小得多,但仍然是占据了一部分的边框。




在侧面可以看到横着摆放的12VHPWR接口,即便RTX 4070的TGP也就200W,不过NVIDIA还是附送了一条双8PIN转12VHPWR电源线。附带一提,这次RTX 4070的部分非公版显卡采用的是单8PIN接口,我们也将会有对应的评测,请大家保持关注!

另外,侧边的这个GEFORCE RTX标志并不会发光,这大概很符合一些玩家的审美。

这次RTX 4070的挡板也有较大的改动,变得和RTX 4090/4080一样,是四个大的出风口。而尾部则没有什么变化,不过毕竟是一张1千克左右的显卡,不设计用于固定的螺丝孔位也很正常。



拆解:紧凑的PCB和熟悉的供电方案
正如其他RTX 40系列FE显卡一样,RTX 4070的PCB也是极为紧凑的。事实上,如此小巧的PCB定会让人思考,即便我们已经能毫不费力地将RTX 4070 FE安装在A4构型的ITX机箱上,厂商们还有没有可能再把该型号的显卡做小一点呢?

虽说RTX 4070 FE也是异形PCB,不过右侧并没有RTX 4090/4080 FE那样尖锐,而是一个圆弧形。位于正中间的,自然是AD104核心,生产日期为22年第31周,也就是去年8月初左右。一般来说,核心丝印的第五行会印有核心的具体型号,格式大概就像AD104-xxx-xxx,但我们手上的这块并没有。

6颗显存分布在核心的左侧和下方,如果经常看我们RTX 4070 Ti评测的朋友应该马上就能认出D8BZC这一零件号码。这是美光的GDDR6X显存,型号为MT61K512M32KPA-21,单颗容量为2GB,位宽为32bit,合计12GB,位宽192bit。


供电设计方面,RTX 4070 FE采用了6 + 2相供电设计。PWM芯片都集中在PCB背面,核心PWM在靠近挡板的一侧,是uPI的uP9512R,一款8相的PWM芯片,至于显存PWM则在圆弧边缘附近,为uPI的uP9529Q,是3相的PWM芯片。显存PWM芯片下方还有一块uPI uS5650Q芯片,起到一个监控电流和电压的作用。


核心和显存所用的MOSFET均是来自安森美的NCP302150。

测试平台

这次的测试平台采用了酷睿i9-13900K、ROG MAXIMUS Z790 HERO和32GB双通道DDR5-6000内存的组合,可以确保RTX 4070以及其他显卡充分的性能发挥。参加测试的NVIDIA显卡有RTX 3070 Ti,严格来说它是上一级的卡,但是这次RTX 4070的MSRP和它是一致的,所以我们选了它。还有更高一级的RTX 3080和前代的RTX 2070 Super,后者可以说是RTX 4070这次的“任务目标”。AMD显卡方面,我们选择的是Radeon RX 6800 XT。

理论性能测试
我们使用3DMark来进行基准性能的测试。测试项目包括Speed Way;Time Spy、Time Spy Extreme;Fire Strike、Fire Strike Extreme、Fire Strike Ultra;Port Royal。
其中,Speed Way测试的是显卡在DirectX12 Ultimate中的性能表现,包含DXR光追,分辨率为1440P;Time Spy和Time Spy Extreme测试的是显卡在DirectX 12中,1440P和2160P下的性能表现;Fire Strike、Fire Strike Extreme和Fire Strike Ultra则是测试显卡在DirectX 11中,1080P、1440P和2160P下的性能表现;Port Royal是针对显卡光线追踪性能的测试。

在DX11中,RTX 4070对RTX 3070 Ti有着约14%的领先优势,而相比RTX 2070 Super,RTX 4070更是有着接近翻倍的性能。在1440P及以下的测试里面,RTX 4070有着和RTX 3080相差无几的分数,其中Fire Strike Extreme的分数更是只有0.7%差距;但在2160P下,RTX 3080比RTX 4070拥有稍高的性能。
到了DX12里面,RTX 4070和RTX 3070 Ti、RTX 2070 Super两张前代同级显卡的差距拉得更大了一点。而它和RTX 3080的差距不仅在DX12测试中变得更小,在Port Royal和Speed Way两个针对新技术的测试中也是如此。某种意义上,我们也可以把RTX 4070和RTX 3080划个等号。
至于对家AMD的Radeon RX 6800 XT在3DMark中的表现可谓一骑绝尘,只是在涉及光追的测试中与RTX 4070、RTX 3080有着较大的差距。这也许会让人产生疑问:我们用它来对比是否会显得不太公平呢?
在接下来的游戏测试中,大家会发现,其实情况并不是这样。
游戏性能测试:大超RTX 3070 Ti,和RTX 3080不相上下
在这里解释一下我们为何选择1080P、1440P和2160P三个分辨率:
首先,NVIDIA对RTX 4070的定位是一张1440P@100+FPS游戏卡;其次,从理论性能测试中,我们知道RTX 4070有着约等于RTX 3080的实力,而后者在推出时是一张定位2160P的卡;最后,便是相当一部分持有前代显卡的玩家仍然在使用1080P分辨率的显示器。当然还有一个原因,那就是多分辨率游戏也算是测试的惯例。
这次的光栅游戏共有13款,包含3款电竞游戏和网游,以及10款3A游戏。因为电竞游戏和网游比较强调高帧率,所以我们把他们独立了开来,它们的横坐标轴最大值也会比3A游戏高上不少。
光追游戏的话自然就全是3A了,这次一共有7款光追游戏。
设置方面,所有游戏都会设置成全屏独占、垂直同步关闭、帧率无限制、渲染分辨率固定为1.0;画面特效均为整体设置上的最高;另外,超分辨率是不启用的。光追游戏则在这个基础上把相关选项打开,并把品质设置为最高。不过,如果部分游戏的整体设置带有光追选项的话,比如《赛博朋克2077》的“光线追踪:超级”,我们则优先采用整体设置。
光栅游戏 1080P


(1440P)


2160P


在光栅游戏这里,1080P、1440P分辨率下,各张显卡之间的差距还是比较一致的。具体表现为RTX 4070平均领先RTX 3070 Ti约15%,比RTX 2070 Super平均快约40%。和RTX 3080相比则是互有胜负,不过总的来说,在这13个游戏里面,RTX 4070帧率较高的游戏是占据多数的。
到了2160P这一个定义上不属于RTX 4070而属于RTX 3080的分辨率上,就产生了一点微妙的变化:RTX 3080表现显然更好一些。当然,它们两者的差距也很小,基本上就是1440P的表现互相调换了一下。事实上,RTX 4070是能够以4K原生分辨率流畅运行大部分游戏的,而《赛博朋克2077》、《巫师3:狂猎》这些可能就要依靠动态分辨率或DLSS了。
而与RX 6800 XT对比的话,我们会发现在三个分辨率下,它跟RTX 4070、RTX 3080都是打得有来有回的,不过在1440P及以下的分辨率中,RTX 4070的赢面显然更大。当然,不可否认在《使命召唤:现代战争2》等一些游戏里面,拥有更大容量显存的RX 6800 XT是领跑的。
光追游戏1080P

1440P

2160P

光追游戏向来是RTX系列显卡的主场,从RTX 20系列再到30、40系列,我们能很清晰地看到每一代都带来的显著的进步。对于现时的光追游戏来说,RTX 2070 Super仅达到了流畅线,RTX 30和40系列显卡显然是更好的选择。而RTX 4070在光追这块的性能比RTX 3070 Ti要高上20%左右,跟上代旗舰级的RTX 3080是持平的。
而跟Radeon RX 6800 XT相比的话,RTX 4070和它其实也称得上是竞争激烈。不过在《赛博朋克2077》还有《看门狗:军团》这些游戏里面,RTX 4070还是拥有较大优势的。
DLSS性能测试:帧生成技术是独门武器
虽然时至今日还是有部分玩家或读者对各种超分辨率技术表现出一种质疑的态度,但总体数量来说,启用这些画面选项的玩家还是增多的。NVIDIA表示,根据他们的调查数据,现在已经有79%的RTX 40系列玩家、71%的RTX 30系列玩家和68%的RTX 20系列玩家会选择在游戏时打开DLSS。同时,打开光追的玩家占比也是相当高。因此关于DLSS超分辨率,和Ada Lovelace这次新增的DLSS帧生成技术的测试也是包括在本次首测里面的。

这次DLSS性能测试共包含6款游戏,除了《荒野大镖客2》不支持光追以外,其他游戏都是在最高特效 + 光追开启的情况下运行的。鉴于游戏在1080P下的表现都不错,这次测试就包括1440P和2160P两个分辨率。至于DLSS超分辨率(DLSS 2)的设置,我们一概选择的是质量模式,DLSS帧生成的话,则分为开和关两种状态。
考虑到DLSS和其他超分辨率技术比如FSR在具体实现方式上还是有些差别的,所以这次我们就仅在RTX显卡之间进行对比了。
1440P

2160P

跟其他测试的表现类似,在DLSS 2下,RTX 4070与RTX 3070 Ti、RTX 2070 Super拉开了相当大的距离,而与RTX 3080的区别其实非常微小。然而在DLSS帧生成技术的帮助下,RTX 4070是所有卡之中表现最好的,1440P下的部分光追游戏甚至能达到100+FPS。
AI性能测试:Stable Diffusion绘画
最近AI确实很火,除了ChatGPT和New Bing这些在线聊天AI之外,本地部署Stable Diffusion图像生成器也是种不错的玩法。得益于Stable Diffusion懒人安装包,以及一些训练模型聚合网站,普通玩家即使不怎么熟悉机器学习和AI,也能够很快地上手AI图像生成。所以我们也测试了RTX 4070在Stable Diffusion中的性能。
我们所用的模型是v2-1_768-ema-pruned.ckpt,Stable Diffusion 2.1的官方模型。具体设置如下图所示:


经过测试,在该设置下RTX 4070的效率是9.09图/分钟,比RTX 3070 Ti快了将近26%。相比RTX 2070 Super,效率更是翻倍。如果要生成细节更多、分辨率更大的图的话,其他显卡和RTX 4070的差距将会更加明显。
RTX VSR:令视频画面更清晰
RTX VSR是一项可以显著提升低画质视频清晰度的技术。它在早些时候就已经实装在Chrome浏览器上并适用于在线的视频播放、还有直播。我们之前也做过相应的体验。现在伴随着RTX 4070的推出,RTX VSR也来到了本地播放器上,VLC是目前首个支持RTX VSR技术的播放器。在这里我们也稍作展示,从对比图可以看到,经过VSR增强的720P《战地2042》视频有着更为锐利的UI和字体,游戏内物体的边缘也更为清晰。


原生720原生720打开VSR打开VSR
温度测试:平均满载温度约65摄氏度
我们是在开放式平台上对显卡的温度进行测试的,测试时室温为24.5摄氏度,使用GPU-Z的Log to File功能记录。待机温度是在进入系统后不进行任何操作获得,摘录其中10分钟的温度,满负载时的温度则是通过运行3DMark中的Time Spy压力测试获得,同样是摘录10分钟的温度。
RTX 4070 FE是有风扇智能启停功能的,因此在待机时,温度是会缓慢上升的。不过虽说温度确实是上升了,但也只是从37度缓慢爬升到39.4度而已。而满载时,温度会在65度上下浮动,最高温也仅为66.8度。考虑到RTX 4070 FE的小巧体积和纯铜基座 + 四热管的散热设计,这种表现着实很出色。

功耗测试:待机功耗极低,平均满载功耗约200W
我们的功耗测试和温度测试是同步进行的,因此各项设置与上面是保持一致的。只不过我们所用的记录软件和硬件是PCAT套件,记录时间是5分钟而已。
RTX 4070 FE的待机功耗非常低,大部分时候就在10-11W之间浮动。平均满载功耗则如官方所示,在200W附近,峰值功耗可达到233W。

噪音测试:30.2dBA足够安静
RTX 4070 FE在满载时风扇的转速其实也不算高,最高也就1660RPM左右。为了测试它的噪音水平,我们在环境噪音在约18.4dBA的消音房中进行了测试。噪声检测仪与显卡的距离为50cm。测得的结果为30.2dBA。看来RTX 4070 FE不仅体积小,声响也是同样小的。

超频测试
我们使用Afterburner对RTX 4070进行了手动超频。GPU可提升250MHz,显存可提升150MHz。最终的显卡分数为18994,领先幅度为5.9%。


总结:该升级了
RTX 4070作为一张进一步面向主流的RTX 40系列显卡,就性能来说有着远超前代同价格显卡RTX 3070 Ti的表现,即便与更上一级的RTX 3080相比也是不落下风。再加上Ada Lovelace架构所带来的DLSS帧生成技术,在对应的游戏中,RTX 4070甚至可以获得比RTX 3080更高的帧率。而与AMD Radeon相比的话,RTX 4070在实际表现中也是不输RX 6800 XT。当然,跟RTX 4070 Ti一样,从显存容量及位宽的配置上可以看出RTX 4070始终是面向1440P分辨率的一张显卡,2160P对于它来说还是有点勉强的,1440P@144Hz乃至更高刷新率的屏幕才是最适合它的。

除了性能外,得益于Ada Lovelace架构和更新的制程工艺,RTX 4070在功耗和温度上的表现也非常出色。本次评测的RTX 4070 FE凭借其紧凑的构型,相信会受到诸位ITX玩家的喜爱。其实个人也希望厂商能在接下来的时间里,推出一些更为迷你小巧的,符合RTX 4070功耗表现的显卡。
显卡迷你天梯榜 (完整显卡天梯榜)

至于开头说到的RTX 4070的任务目标,在经过众多测试后,我们认为RTX 4070是能够完成的,毕竟单就光栅性能来说,RTX 4070相较于前代同级显卡的提升已经是足够可观了,就更别提NVIDIA十分拿手的光追和DLSS性能了。而在价格方面,本次RTX 4070的MSRP比前代稍高,来到了RTX 3070 Ti的水平,为599美元,国内则是4799元人民币起步。考虑到性能提升的幅度,RTX 4070确实也值得持有前代同级或更低显卡的玩家升级。当然,一般来说这个升级肯定是换全套的,从预算这方面去讲的话,RTX 4070会是万元及以内装机的一个好选择。
[注:本文部分图片来自互联网!未经授权,不得转载!每天跟着我们读更多的书]
互推传媒文章转载自第三方或本站原创生产,如需转载,请联系版权方授权,如有内容如侵犯了你的权益,请联系我们进行删除!
如若转载,请注明出处:http://www.hfwlcm.com/info/16448.html
相关文章
-

前言:我是李迪,一名数码产品资深剁手。作为剁手,我深谙网络选购技巧,通过我的选购指南和攻略,很多用户都避免了购物的雷区。最近很多朋友强烈要求李迪谈一谈网络电视盒子
-

没有统一的评判标准,单靠功能的多寡或者价格的高低来对网络机顶盒进行排名的话,是一件很难,结果也不会合理的排名。因为目前的网络机顶盒产品,差异非常大,种类之多达到了
-

时间过得飞快,圣诞节,元旦节之后,天猫还设计了一个年货节,让大家准备好买年货。不过,除了各种吃的、穿的,年货节还有一件数码产品也是必买的。那就是——网络电视盒子,
-
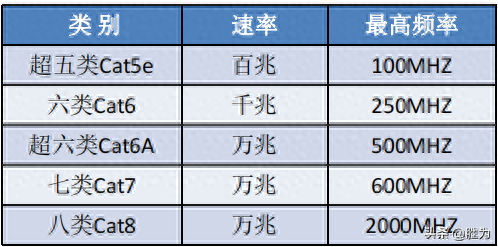
双绞线(TP:Twisted Pairwire)是综合布线工程中最常用的一种传输介质。双绞线由两根具有绝缘保护层的铜导线组成。把两根绝缘的铜导线按一定密度互相绞在一起,可降低信号干扰的程度,每一
-

在现代社会中,网络已经成为了人们生活中必不可少的一部分。在家庭装修中,选择合适的网线规格就显得至关重要。因为一旦装修完成,更改网线布线就会变得非常困难和麻烦。因此
-

宽带、网线和光纤有什么区别:一、网线首先,来介绍网线,网线是局域网连接中必不可少的一种通信连接设备,可分为双绞线、同轴电缆、光缆三种。其中,双绞线是由许多绝缘的对
-

2023年9月,我向大家推荐一些适合入门级的WiFi6路由器。在这个新的时代,Intel新一代主板大量搭载了Wi-Fi7无线网卡,这将为路由器市场带来新的机遇。我是DIY阿鹿君,很高兴与大家分享
-

618巅峰冲刺,什么Wi-Fi 6路由器值得买?当然是选择华硕路由器啦!从技术实力、使用体验、用户口碑来看,华硕路由器都是行业佼佼者,也是发烧友的首选推荐!更关键的是,今年618的