ChatGPT笨了,还是老了?
原文来源:科技新知

图片来源:由无界 AI 生成
“过去的表现并不能保证将来的结果。”这是大多数金融理财模型的小字。
在产品业务内部,这被称之为模型漂移、衰退或过时。事情会发生变化,模型性能会随着时间的推移而下降。最终的衡量标准是模型质量指标,可以是准确率、平均错误率,也可以是一些下游业务的KPI,比如点击率。
没有任何模型可以永远有效,但衰退的速度各不相同。有些产品可以使用多年而无需更新,例如某些计算机视觉或语言模型,或者是在隔离、稳定环境中的任何决策系统,比如常见的实验条件下。
想要保证模型精度,就需要每天对新数据进行训练,这是机器学习模型的范式缺陷,也使得人工智能部署,不能像软件部署一样可以一劳永逸。后者被创造了几十年,目前最先进的AI产品,依然使用着早年的软件技术。只要仍然有用,即时技术已经过时,它们依然可以长存于每一个字节中。
不过被称为人工智能最前沿的产品,以ChatGPT为代表的大模型,在遭遇人气衰减后,迎来是否正在过时和衰老的质疑。
无风不起浪。用户在ChatGPT上花费的时间越来越少,从3月份的8.7分钟降至8月份的7分钟。侧面反映出,当大模型工具的供给侧迅猛增长,仅仅只是生产力工具的ChatGPT似乎并不足以成为主流使用人群Z世代的心头好。
一时的人气不足以动摇致力于成为AI时代应用商店的OpenAI霸主地位。更核心的问题是,ChatGPT生产力的老化,才是不少老用户信任度下降的主因。自5月份开始,OpenAI论坛里讨论GPT-4性能不如以前的帖子,就一直在发酵。
那么ChatGPT过时了吗?以ChatGPT为代表的大模型会像过去的机器学习模型一样衰老吗?不理解这些问题,就不能在层出不穷的大模型热潮之下,找到人与机器的可持续发展之道。
01 ChatGPT过时了吗?
来自Salesforce AI软件服务商最新的一份数据显示,有67%的大模型使用者是Z世代或者千禧一代;很少使用生成AI或在这方面落伍的人群中,68%以上的人是X一代或婴儿潮一代。
代际差异说明Z世代正在成为拥抱大模型的主流人群。Salesforce产品营销人员Kelly Eliyahu表示:“Z世代实际上是AI一代,他们构成了超级用户群体。70%的Z世代正在使用生成式AI,至少有一半的人每周或更长时间使用它。”
不过作为大模型产品的领军者,ChatGPT在Z世代人群中的表现并不出色。

根据市场调研机构Similarweb 7月份的数据显示,ChatGPT在Z世代人群中的使用占比为27%,低于4月份的30%。作为对比,另外一款可以让用户自己设计人工智能角色的大模型产品,Character.ai在18-24岁年龄段的人群中渗透率为60%。
得益于Z世代的追捧,Character.ai的iOS和Android应用程序目前在美国的月活跃用户数为420万,距离移动端ChatGPT的600万月活,日益接近。
和ChatGPT的对话式AI不一样,Character.AI在此基础上加入个性化、UGC两大核心功能,使其有了比前者更丰富的使用场景。
一方面,用户可以根据个人需求自定义AI角色,满足Z世代个性化定制的需求。同时这些用户自主创建的AI角色,也可以被平台所有用户使用,构建AI社区氛围。比如此前在社交媒体平台传播出圈的苏格拉底、God等虚拟人物,以及官方自主创建的马斯克等商业名人的AI形象。
另一方面,个性化的深度定制+群聊功能,也使得用户对于平台产生情感智能依赖。很多社交媒体平台的用户公开评价显示,因为聊天体验过于逼真,就像“自己创作的角色拥有生命,就像在与真人交谈”,“是迄今为止最接近假想朋友、守护天使的东西”。
可能是来自Character.AI的压力,2023年8月16日OpenAI在官网发布了一则简短声明,宣布收购美国初创企业Global Illumination,并将整个团队纳入麾下。这家仅有两年历史八位员工的小公司,主营业务是利用人工智能创建巧妙工具、数字基建和数字体验。
收购行为的背后,很可能意味着OpenAI将致力以丰富的方式,改善目前的大模型数字体验。
02 人工智能的衰老化
ChatGPT在大模型数字体验层面的老化,影响了其杀时间的效果。作为生产力工具,其生成结果准确性的飘忽不定,也正在影响其用户黏性。
此前根据Salesforce的调查显示,有近六成的大模型使用者认为,他们正在通过累计时间的训练掌握这项技术。不过目前这种技术的掌握,正在随着时间的迁移发生变化。
早在5月份,就有大模型老用户在OpenAI论坛上开始抱怨GPT-4,“在以前表现良好的事物上表现出困难”。据《Business Insider》7月份报道称,很多老用户将GPT-4与其以前的推理能力和其他输出相比,形容为“懒惰”和“愚笨”。
由于官方并未对此作出回应,人们开始对GPT-4性能下降的原因进行推测,会不会是因为此前OpenAI的现金流问题?主流猜测集中在成本优化导致的性能下降方面。一些研究者称,OpenAI可能在API后面使用了规模较小的模型,以降低运行ChatGPT的成本。
不过这个可能性随后被OpenAI的产品副总裁Peter Welinder否认。他在社交媒体上表示:“我们没有让GPT-4变得更笨,目前的一个假设是,当你更加频繁地使用它时,会开始注意到之前没有注意到的问题。”
更多的人、更长时间的使用,暴露了ChatGPT的局限性。对于这种假设,研究者试图通过更严谨的实验呈现“ChatGPT性能和时间关系的变化”。

来自斯坦福大学和加州大学伯克利分校在7月份提交的一篇题为《How is ChatGPT's behavior changing over time?》的研究论文显示:同一个版本的大模型,确实可以在相对较短的时间内发生巨大变化。
从3月份到6月份,研究者测试了GPT-3.5和GPT-4两个版本,采集了四个常见的基准任务数学问题、回答敏感问题、代码生成和视觉推理的生成结果,并进行评估。结果显示,无论是GPT-3.5还是GPT-4,二者的性能和生成结果,都有可能随时间而变化。
数学能力方面,GPT-4(2023年3月)在识别质数与合数方面表现得相当不错(84%准确率),但是GPT-4(2023年6月)在相同问题上的表现不佳(51%准确率)。有趣的是,CPT-3.5在这个任务上6月份的表现要比3月份好得多。
不过在敏感问题方面,GPT-4在6月份回答敏感性问题的意愿较3月份下降;代码能力方面,GPT-4和GPT-3.5,都在6月份表现出比3月份更多的错误。研究者认为,虽然ChatGPT的性能和时间没有明显的线性关系,但是准确性确实会飘忽不定。
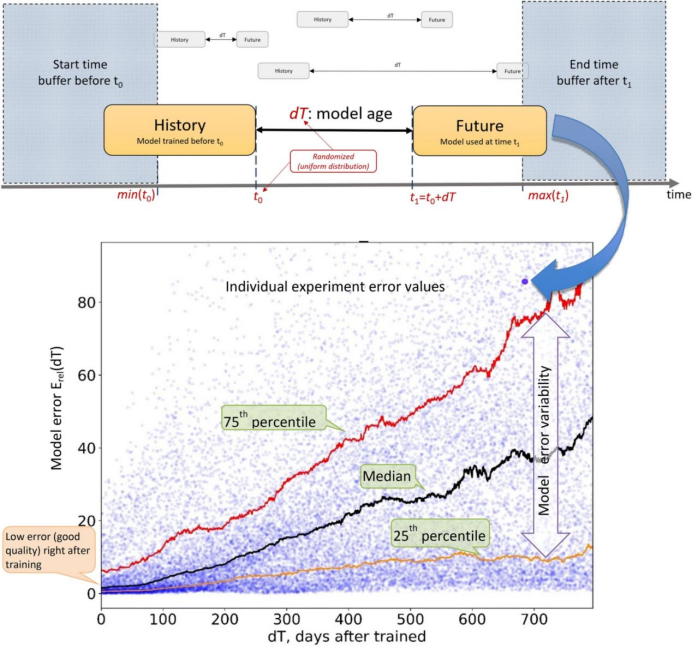
这不仅是ChatGPT自己的问题,也是此前所有AI模型的通病。根据麻省理工学院、哈佛大学、蒙特雷大学和剑桥大学2022年的一项研究表明,91%的机器学习模型都会随着时间的推移而退化,研究者将这种现象称为“人工智能老化”。
例如,Google Health曾经开发了一种深度学习模型,可以通过患者的眼睛扫描来检测视网膜疾病。该模型在训练阶段的准确率达到90%,但在现实生活中却无法提供准确的结果。主要是因为在实验室,采用高质量的训练数据,但是现实世界的眼睛扫描质量较低。
受制于机器学习模型老化的情况,过去走出实验室的AI技术,以单一的语音识别技术为主,智能音箱等产品因此最先普及。根据美国人口普查局2018年对58.3万家美国公司的调查,只有2.8%使用机器学习模型来为其运营带来优势。
不过伴随着大模型智能涌现能力的突破,机器学习模型的老化速度明显减弱,逐渐走出实验室面向更广泛的受众。不过,涌现能力的黑盒下仍有不可预测性,让不少人对于ChatGPT能否长期保持AI性能的不断提升提出质疑。
03 黑盒下的抗衰老性
人工智能老化的本质,其实是机器学习模型的范式缺陷。
过往,机器学习模型是按照具体任务和具体数据的对应关系进行训练。通过大量的例子,先教给模型,那个领域中什么是好,什么是坏,再调节一下模型的权重,从而输出恰当的结果。这种思路下,每做一些新的事情,或者数据分布有明显变化,都要重新训练一遍模型。
新事情和新数据无穷无尽,模型就只能刷新。但是模型的刷新也会导致过去做得好的事情突然做不好了,进一步限制应用。总结来看,传统的机器学习模型中,数据飞轮本质是为了迭代模型,用新模型解决新问题的范式。
不过以ChatGPT为代表的大模型,涌现出自主学习能力,突破了这种范式。过往的机器学习,是先“吃”数据,之后“模仿”,基于的是对应关系;ChatGPT类的大模型,是“教”数据,之后“理解”,基于的是“内在逻辑”。
这种情况下,大模型本身不发生变化,理论上可以永葆青春。不过也有从业人士表示,正如大模型的智能涌现一样,是非线性发展、不可预测的,是突然就有的。对于大模型是否会随着时间发生衰老,涌现出难以预测的不可确定性也是未知的。
换句话说,ChatGPT在涌现出难以理论化推导的智能性能后,也开始涌现出难以预测的不可确定性。
对于“涌现”的黑盒性,9月6日在百川智能Baichuan2开源大模型发布会上,中国科学院院士、清华大学人工智能研究院名誉院长张钹表示:“到现在为止,全世界对大模型的理论工作原理、所产生的现象都是一头雾水,所有的结论都推导产生了涌现现象。所谓涌现就是给自己一个退路,解释不清楚的情况下就说它是涌现。实际上反映了我们对它一点不清楚。”
在其看来,大模型为什么会产生幻觉这个问题,涉及到ChatGPT跟人类自然语言生成原理的不一样。最根本的区别在于,ChatGPT生成的语言是外部驱动的,而人类的语言是在自己意图的情况下驱动的,所以ChatGPT内容的正确性和合理性不能保证。
在经历过一系列概念炒作跟风上车之后,对于致力于开发生产力基础模型的人来说,面临的挑战将是如何确保其产品持续输出结果的可靠性和准确性。
不过对于大模型相关的娱乐产品而言,正如Character.AI 联合创始人Noam Shazeer在《纽约时报》上所说:“这些系统并不是为真相而设计的。它们是为合理的对话而设计的。”换句话说,它们是自信的废话艺术家。大模型的巨浪已然开始分流。
参考资料:
- Gizmodo-Is ChatGPT Getting Worse?
- TechCrunch-Al app Character.ai is catching up to ChatGPT in the US
- Machine Learning Monitoring- Why You Should Care About Data and Concept Drift
- M小姐沿习录-关于ChatGPT的五个最重要问题
- 清华大学人工智能国际治理研究院-对大模型的研究很迫切,不能解释不清楚就说“涌现”
[注:本文部分图片来自互联网!未经授权,不得转载!每天跟着我们读更多的书]
互推传媒文章转载自第三方或本站原创生产,如需转载,请联系版权方授权,如有内容如侵犯了你的权益,请联系我们进行删除!
如若转载,请注明出处:http://www.hfwlcm.com/info/178302.html
相关文章
Web3 堆栈:web3 如何提供比 web2 更好的用户体验?
许多 web3怀疑者在使用web3相关产品之后很快就批评说用户体验很糟糕,即使是 web3的拥护者也经常承认用户体验可能没有那么好,但去中心化带来的良好特性能弥补这个缺陷。 事实证明...

加密大V Ansem长文展望2022年:公布个人投资组合
2022-01-02T15:23:34.000+0000 展望2022年,我们将看到,在加密货币的宏观牛市周期中,某些行业是否会继续经历熊市周期。交易者的困难在于确定哪些代币在目前市场上存在错误定价,如何利...
三星将在其智能电视上提供“NFT聚合平台”
1月3日消息,三星在新闻稿中表示,2022年将在其MicroLed、Neo QLED和The Frame等型号的智能电视上提供“NFT聚合平台”,允许用户直接浏览和购买NFT。该平台从多个市场引入NFT,因此用户可以...
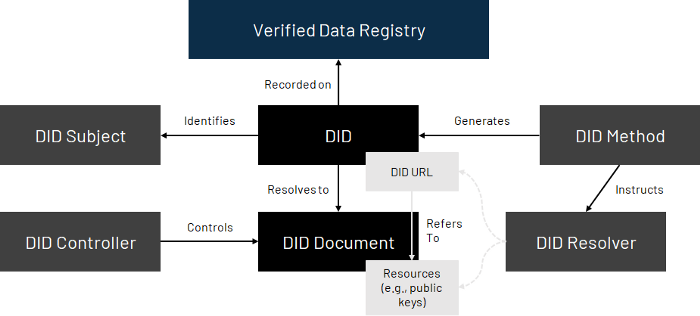
极易被忽视的DID:是通往Web3的护照
介绍 互联网的创建没有为人们提供一个原生的身份层。正因为如此,数字身份的问题被归结为网站和应用程序。这种孤立的方法在互联网的早期可能是合适的,但随着现在数十亿人上网...

这家元宇宙独角兽:想让你在虚拟中真实赚到钱
今年 3 月,Roblox 以 450 亿美元的市值风风火火地在纽交所上市。它成为「元宇宙第一股」后,同类公司也集体迎来了一波新风口下的飞速增长。 同样在 Roblox 上市的 3 月,一家名叫 Rec...

NewB.Farm收益农场新添Zap功能 将简单做到极致
NewB.Farm收益农场为了让更多新用户进入DeFi的门栏,添加了Zap功能,将简单做到极致! DeFi的全称是Decentralized Finance,即“去中心化金融”,可以说是现代新金融,它不受时间和地域限制地...
Hasu 对话 Su Zhu:以太坊VS新公链 屠龙者正变成巨龙
Su Zhu (现推特名 Zhu Su) ,三箭资本创始人,加密世界中最有权势的男人之一,现在多了一个身份标签,被Cryptobriefing评选为2021加密世界十大“恶棍”之首,一切皆源于此前Su Zhu与Syntheti...

Web 3.0:一场危险的社会实验
一个集齐了区块链、比特币、NFT、元宇宙的大一统体系。 你知道什么是Constitution DAO吗?你听说过Axie Infinity、ChainRoblox吗?或许你对这些英文单词还比较陌生,但是Web 3.0一定会是你近期...