基于VMD-PE-CNN的混凝土坝变形预测模型
《水利水电技术(中英文)》官网网址https://sjwj.cbpt.cnki.net
摘 要:
为了进一步提高混凝土坝变形预测精度,基于“先分解再重构”的思想,将变分模态分解(VMD)、排列熵(PE)与卷积神经网络(CNN)相结合,提出了一种混凝土坝变形预测模型。通过VMD和计算模态分解余量的PE将原始实测变形时间序列数据自适应地分解为一系列具有不同频域尺度特征的模态分量,然后将每个模态分量作为单独的子序列,采用CNN直接对各子序列进行时域建模并预测,最后将各个子序列的预测值叠加重构得到最终的大坝变形预测值。实测数据计算结果表明:采用计算模态分解余量PE的方法可以得到最优的模态分量个数,实现实测数据的最优分解;较之于CNN和LSTM模型,VMD-PE-CNN模型在测试数据上的均方根误差分别降低了61.8%和65.5%,显示出更强的预测能力。
关键词:
变分模态分解;卷积神经网络;排列熵;变形预测;深度学习;
作者简介:张健飞(1977—),男,副教授,博士,主要从事结构健康诊断和大坝安全监控研究。
基金:
国家自然科学基金项目(12072105);
引用:
张健飞, 衡琰. 基于 VMD-PE-CNN 的混凝土坝变形预测模型[J]. 水利水电技术(中英文), 2022, 53(11): 100- 109.
ZHANG Jianfei, HENG Yan. VMD-PE-CNN-based deformation prediction model of concrete dam [J]. Water Resources and Hydropower Engineering, 2022, 53(11): 100- 109.
0 引 言
大坝是水利、交通、能源等行业的重要基础设施,截至 2020年4月,全球进入国际大坝委员会World Register of Dams(WRD)数据库的注册大坝超过58 700座。混凝土坝是大坝采用的主要坝型之一,目前全球坝高250 m以上的大坝超过一半为混凝土坝。这些混凝土坝由于在运行过程中受到动静循环荷载、恶劣环境侵蚀、人为破坏以及突发性灾害等因素作用,其局部和整体安全性能将会逐步下降。变形是一种能够反映混凝土坝安全状态的综合变量,漫顶、坝体开裂、坝体倾覆、坝体滑动和拱座失稳等混凝土坝典型失事模式都会导致坝体局部或者整体变形的异常,因此依据实测数据建立变形预测模型对混凝土坝的安全运行具有重要意义。目前应用较广的混凝土坝变形预测模型主要有常规模型,即统计模型、确定性模型和混合模型,以及组合模型、时空分布模型和人工智能模型等。传统的大坝安全监控模型含有统计特性,模型精度较大程度上取决于建模因子的选择是否恰当,且难以表达复杂的非线性关系,抗噪声能力差。与传统模型相比,人工神经网络具有自组织性、自适应性、联想能力、自学习能力,且具有极强的非线性映射能力,能够很好地解决工程中遇到的复杂的非线性问题,已经在大坝安全监控中得到了较多应用。
随着深度学习的快速发展,长短期记忆网络(Long Short-Term Memory, LSTM)和卷积神经网络(Convolutional Neural Networks, CNN)等深度神经网络开始在混凝土坝变形预测中得到研究和应用。基于CNN的方法一般通过对水位、气温和时效等影响因素进行建模实现变形预测;基于LSTM的方法则直接在时域上对实测变形数据进行建模预测。魏道红等建立了一种基于CNN的混凝土坝变形预测模型,利用监测变形数据的水压分量、温度分量和时效分量构建模型的训练和测试样本数据,相比于浅层神经网络模型和统计模型,具有更高的预测精度和更加稳定的性能。胡安玉等采用长短期记忆网络(LSTM)提取变形监测数据在长短时间尺度上的关联性,利用自回归差分移动平均模型(Arima)进行预测误差修正,建立了基于 LSTM-Arima的大坝变形组合预测模型,较之Arima 模型和支持向量机(SVM)模型,取得了更优的预测结果。QU等基于粗糙集理论和LSTM建立了混凝土坝单测点和多测点变形预测模型,建立了评价模型精度、鲁棒性和泛化性能的定量指标,工程实例表明该模型可以定量获取大坝变形的影响因子及其重要性。YANG等提出了一种基于LSTM和注意力机制的混凝土坝变形预测方法,采用LSTM处理大坝变形中的长期依赖性问题,采用注意力机制反映影响大坝变形的显著因素,较之RNN和LSTM,该方法在工程实例中显示出更高的预测精度。REN等构建了一种基于混合注意力机制LSTM的混凝土坝变形预测模型,采用注意力机制选择最重要的影响因子和时间片段,在提高预测精度的同时也提高了模型的物理可解释性。LI等提出了一种基于LSTM的大坝变形两阶段预测模型,第一阶段学习变形与影响因子之间的关系,第二阶段提取监测系统的随机特征,最后将两阶段之和作为最终预测值,实例分析表明该模型较之浅层学习模型和单阶段深度模型具有更高的预测精度。
在实际工程中,大坝实测变形数据序列具有非线性和非平稳的特征,同时由于环境和测量仪器等原因,不可避免地存在一定程度的噪声,如果直接基于原始变形监测数据进行建模和预测,则容易产生较大预测误差。将原始变形监测数据分解为多个子序列分别进行预测后再重构,可以降低原始数据的复杂度和非平稳性,从而可以降低预测难度、提高预测精度。目前常用的分解方法有小波分析、经验模态分解(Empirical Mode Decomposition, EMD)和变分模态分解(Variational Mode Decomposition, VMD)。周兰庭等提出一种基于WA-LSTM-ARIMA的大坝变形组合预测模型,首先采用小波多分辨率分析对原始监测序列进行多尺度分解,然后对高频分量进行LSTM建模预测,对于低频趋势性分量则建立ARIMA模型进行预测,与传统模型相比,该模型的预测精度更高。马佳佳等运用集合经验模态分解(EEMD)将变形监测数据分解为多尺度变形分量,对高频分量采取LSTM进行预测,对低频分量采用多元线性回归(MLR)进行预测,最终通过分量重构得到大坝变形预测结果,与传统模型相比,EEMD-LSTM-MLR模型具有更低的平均绝对误差、平均绝对百分误差和均方根误差。宋洋等提出了基于CEEMDAN-PE-LSTM的混凝土坝变形预测模型,利用自适应噪声完全集合经验模态分解(CEEMDAN)将原始变形数据分解为具有不同频率和不同复杂度的的一系列固有模态函数(IMF),将排列熵(PE)相近的IMF分量进行合并重组,基于LSTM对各重组序列进行预测后叠加重构得到最终变形预测值,与常规模型相比,CEEMDAN-PE-LSTM模型预测精度得到明显提高,对非线性数据序列具有更好的预测能力。侯回位等构建了一种EEMD-SE-LSTM模型用于混凝土变形监测,首先利用 EEMD 对原始数据序列进行分解,并以原始序列样本熵(SE)作为基准对每个分量序列进行重构,然后对重构后的各序列建立LSTM 模型进行预测,最后把各预测值叠加得到最终预测结果,与EMD-LSTM、LSTM 和 SVM 模型相比,EEMD-SE-LSTM模型具有更高的预测精度。然而,小波分析不具有自适应特征,EMD则存在模态混叠等问题,变分模态分解(Variational Mode Decomposition, VMD)是一种自适应分解算法,可以将信号从低频到高频进行有效分解。陈竹安等提出一种VMD和LSTM相组合的预测模型,首先对大坝变形监测数据进行变分模态分解,并利用LSTM对各模态分量进行预测,然后累加各模态分量的预测值完成重构,最后采用工程实例验证了模型的有效性和稳定性。
本文采用CNN直接在时域上处理变形监测时间序列数据,提取数据在时域上依赖信息,通过与VMD和PE相结合,提出了一种基于VMD-PE-CNN的变形预测模型。首先采用VMD将变形监测数据序列分解为一组具有不同频率尺度特征且相对平稳的固有模态分量,减少非线性和非平稳性的影响,降低预测难度,VMD中的最优模态分量数通过计算分解余量的排列熵确定;然后采用CNN直接对每个模态分量进行预测,根据不同模态分量的特点挖掘原始数据中的多尺度特征;最后将各个分量的预测值叠加得到最终的预测值。
1 基于VMD-PE-CNN的预测模型
1.1 变分模态分解
VMD将分解过程转化到变分框架中,通过计算约束变分模型的最优解来确定每个固有模态以及对应的中心频率,实现原始时间序列从低频到高频的有效分解,本文中的原始时间序列为变形监测数据序列。VMD 的核心部分是变分问题的构建和求解,其主要步骤如下:
(1)假设原始信号f被分解为K个分量,构造约束变分模型
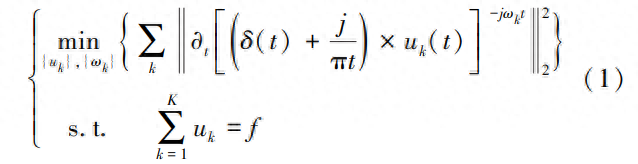
式中,∂t表示求偏导;δ(t)为狄拉克函数;K为模态分量的个数;{uk}、{ωk}分别为第k个模态分量及其对应的中心频率。
(2)将式(1)的约束性变分问题转化为非约束性问题,得到增广拉格朗日表达式

式中,λ(t)为拉格朗日乘子;α为二次惩罚因子。
(3)应用交替方向乘子法结合傅里叶等距变换求解式(2),直到满足下式

式中,N为最大迭代次数;uk、ωk和λ交替更新,最终得到的最优解即为各固有模态分量uk及其中心频率ωk。
VMD中二次惩罚因子α和模态分量个数K这两个参数对分解效果具有较大影响,对于这两个参数的取值,目前有两种方法:一种是考虑两个参数之间的影响,同时对这两个参数进行寻优,这种方法能够得到最优的参数组合,但是计算量比较大;另一种方法通常是根据经验取定二次惩罚因子α值,单独对模态分量个数K进行寻优,这种方法能够得到较优分解,而且计算效率比较高。
1.2 排列熵
VMD中的模态分量个数对分解结果的准确性具有较大影响,本文通过计算变分模态分解余量的排列熵自动确定模态分量的最优个数,减少了人为设定的主观性。排列熵是一种衡量时间序列复杂度的指标,具有计算简单、抗噪性强等特点,其计算步骤如下:
将模态分解余量看作长度为n的时间序列{x(i),i=1,2,…,n},对其进行相空间重构,得到重构向量

式中,m和τ分别为嵌入维度和延迟时间,J=n-(m-1)τ。
对每个重构向量中的元素按照递增的顺序进行重排序,即第j个重构向量重排序后得到

从而每个重构向量都对应一个符号序列s(l)=(j1,j2,…,jm), l=1,2,…,d。对于m维相空间,符号序列总共有m!种,因此d≤m!。计算每一种符号序列出现的概率为P1,P2,…,Pd,则时间序列{x(i),i=1,2,…,n}的d种不同符号序列的排列熵定义如下

当Pj=1/m!时,HP(m)最大值为ln(m!),将HP(m)进行归一化处理,得到HP=HP/ln(m!)。HP值的大小表示时间序列的混乱程度,HP值越小表示时间序列越有规律性,HP值越大则表示时间序列越混乱。当模态分解余量的HP大于一个阈值时可以认为余量接近随机,其中的有用信息已经基本分解殆尽,此时的模态分量数可以看作最优取值。
1.3 卷积神经网络
CNN包括输入层、卷积层、池化层和全连接层。本文将VMD得到的各个模态分量直接作为CNN的输入数据进行处理。数据在输入模型之前需要进行样本化和归一化处理。归一化就是把测值变换为0和1之间小数;样本化就是将原始序列数据分割成长度为T=Tin+Tout的若干段子序列,作为模型的训练和测试样本,其中Tin为输入序列维度,Tout为输出序列维度,即利用子序列中前Tin个测值预测后Tout个测值,本文是单步预测,因此输出序列维度为1。
卷积层由一系列卷积核组成,用于计算不同的特征图,每一个特征图在生成时,卷积核对于输入来说是共享的,使用不同的卷积核就得到不同的特征图。本文采用CNN对时间序列数据进行处理,因此只在时间域上进行一维卷积和池化运算。一维卷积层特征图的计算一般包含两步:首先利用卷积核对输入序列数据进行卷积操作;然后对每个卷积计算结果施加激活函数。第l层卷积层第k个特征图中第i个位置处的数值zli,ki,kl计算如下

式中,Wlkkl、blkkl分别为第l层第k个卷积核的权系数矩阵和偏移量;yl−1iil-1为第l-1层以第i个位置处的数值为中心的一块输入数据。
式(7)中,生成特征图zl:,k:,kl的卷积核Wlkkl是共享的。激活函数的作用是在卷积神经网络中引入非线性,从而使得卷积神经网络能够提取数据中的非线性特征。令a(·)为非线性激活函数,则卷积特征zli,ki,kl的激活值ali,ki,kl可以按下式计算

目前常用的激活函数有sigmoid、tanh和ReLU等,本文的CNN中采用ReLU激活函数。
池化层的作用是对卷积层中提取的特征进行汇总并对信息进行压缩,从而使卷积神经网络能够抽取的特征范围更广。池化层通常位于卷积层之后,池化层的每一个特征图与与它前面的卷积层相关联。记池化函数为pooling(·),则对于每一个特征图ali,ki,kl,可以得到

式中,Ri为第i个位置处的数值周边的邻近区域,常见的池化操作有取平均值和取最大值,本文采用最大池化。
通过卷积和池化计算得到的CNN输出序列数据为xi(i=1,2,…,M),其中向量xi=(xi,1,xi,2,…,xi,P),P为最后一层卷积层的特征图个数,M根据卷积核尺寸、池化核尺寸、步长等参数确定。
最后将池化层的输出展开成维度为E=M×P的向量后输入全连接层,其计算如下

式中,Wgg′为全连接层的权重系数矩阵;D为预测步数,即输出序列维度Tout。
1.4 基于VMD-PE-CNN的预测模型
本文提出的基于VMD-PE-CNN的预测模型(VMD-PE-CNN模型)首先采用不同模态分量数对原始变形监测数据进行变分模态分解,计算分解余量的排列熵,根据排列熵确定VMD的最优模态分量数;然后,采用最优模态分量数将变形监测数据分解为一系列模态分量,并对每个模态分量进行归一化和样本化,按照一定的比例将样本数据划分成训练集、验证集和测试集;再利用CNN对各个模态分量直接建模,输入样本数据进行训练和预测;最后将各个模态分量的预测值进行叠加重构得到最终的变形预测值。模型的流程结构如图1所示。通过VMD,使得原始监测序列分解为一系列具有一定频率带宽的分量的叠加,每个分量相比原始序列的非平稳性和非线性均得到一定程度降低,从而降低了预测难度。此外,根据分解余量的排列熵计算,当余量接近随机噪声时将其滤除,可以减少噪声对预测精度的干扰。

图1 VMD-PE-CNN模型结构
2 实例分析
五强溪水电站混凝土重力坝坝顶高程117.5 m, 最大坝高87.5 m, 坝顶总长719.7 m, 共分为34个坝段,大坝布置如图2所示。大坝水平位移采用引张线及垂线进行观测,引张线各测点和垂线系统均接入了自动化监测系统,每天自动观测1次。本文选取河床深槽位置的坝高最大的第22号溢流坝段坝顶引张线测点EX2-21的顺河向位移监测数据进行分析,测点位于22号坝段坝顶距上游侧0.45 m处(见图2),测点装置如图3所示。从2014年1月1日到2020年12月27日剔除异常测值后共计2 223组实测数据,按照6∶2∶2的比例划分训练集、验证集和测试集。其中2014年1月1日至2019年5月13日的1778组数据作为训练数据,并按照3∶1的比例划分为训练集和验证集,用于模型的训练;剩余的445组监测数据作为测试数据集,用于测试模型的泛化性能。实测的变形及其对应的上游水位和坝址气温变化曲线如图4所示,坝顶顺河向位移基本上呈年周期变化,主要是受温度影响,在温度降低时,坝顶向下游位移,温度升高时,向上游位移较大,符合混凝土重力坝的变化规律。

图2 大坝布置及测点位置

图3 引张线测点装置

图4 大坝实测变形、水位和气温时程曲线
2.1 神经网络结构和参数
神经网络模型的结构和参数对其性能具有很大的影响,本文利用实测训练数据和网格搜索法对神经网络结构和参数进行了比选寻优,模型的评价指标采用预测值和实测值之间均方根误差(Root Mean Squared Error, RMSE),取5次计算的平均值。对于CNN,比较了包含2组卷积层和池化层的二层网络结构和包含3组卷积层和池化层的三层网络结构,每种结构的搜索参数为卷积核数、卷积核尺寸和池化尺寸,卷积核数的搜索格点为16、32、48,卷积核尺寸搜索格点为2、4、8,池化尺寸搜索格点为1、2、4,共计27种参数组合。得到的最优网络结构为二层结构,相应的最优参数组合为48、8、1。
对于下文参与预测性能比较的LSTM,分别对包含2层LSTM的二层网络结构和包含3层LSTM的三层网络结构的不同参数组合进行了比选,搜索参数为每一层的输出维度,搜索格点为16、32、48,二层结构共计9种参数组合,三层结构共计27种参数组合。采用网格搜索法得到的最优网络结构为二层结构,相应的最优参数组合为48、32。
对于用于预测的输入序列维度Tin,CNN在Tin分别取16、32和48时的预测误差为0.227 6、0.223 2和0.226 5,LSTM的相应预测误差为0.338 6、0.283 7和0.358 7。因此本文中的输入序列维度Tin均取为32。
2.2 模态分解
本文综合考虑计算精度和计算效率,VMD过程中的二次惩罚因子α根据文献[18]取值为2 000,只对模态分量个数K进行优选。首先计算采用不同模态分量数K时变分模态分解余量的排列熵;然后通过计算相同长度的白噪声序列的排列熵确定阈值,从而自适应确定最优模态分量个数。采用不同K时变分模态分解余量的排列熵如表1所列。可以看出:随着K值的增大,模态分解余量的排列熵逐步增加,说明余量越来越不规则,余量中的有用信息越来越少,当排列熵接近1时则说明余量近似于随机序列,不再含有规律性的信息。为了确定一个较优的模态分量个数K,本文计算并得到相同长度的白噪声序列的排列熵为0.995,考虑到余量接近白噪声时,余量中的有用信息已经很小,本文设定的模态分解余量排列熵的阈值为0.99,据此得到的模态分量数K的较优取值为11。归一化后的原始变形监测数据变分模态分解后得到的各个模态分量及分解后的余量如图5所示,可以看出第1阶模态反映一定的趋势变化,后10阶模态具有周期性,余量则近似于随机序列。通过模态分解,原始变形序列中的趋势性和周期性得到了挖掘,从而有助于预测模型更好地理解数据特征,降低预测难度。而且分解余量的排列熵接近白噪声的排列熵,因此通过VMD也达到了将噪声滤除的目的,减少了噪声对预测精度的影响。


图5 变分模态分解模态分量与分解余量
[18] 罗亦泳,黄城,张静影.基于改进 IVMD 的工程结构状态特征分析研究[J].应用基础与工程科学学报,2021,29(4):873-888.LUO Yiyong,HUANG Cheng,ZHANG Jingying.Structural state feature analysis based on improved variational mode decomposition[J].Journal of Basic Science and Engineering,2021,29(4):873-888.
2.3 预测结果与分析
VMD-PE-CNN模型在归一化的训练集和验证集上的训练误差随着训练批次的发展曲线如图6所示,可以看出训练集和验证集上的均方根误差(RMSE)和平均绝对误差(MAE)均能迅速收敛至稳定值,训练误差和验证误差相近,不存在过拟合现象。为了检验排列熵确定的最优模态数的合理性,分别计算了采用不同模态分量数的模型在未归一化训练数据和测试数据上预测误差如图7所示。从图7中可以看出:模态分量个数小于11时,随着模态分量数的增加,模型的训练误差和测试误差均不断下降,但是当模态分量个数大于11时,训练误差继续下降,但是测试误差不降反升,模型开始出现过拟合现象,泛化性能下降,说明本文采用排列熵确定最优模态数的方法具有较好的合理性。

图6 VMD-PE-CNN模型训练曲线

图7 采用不同模态数时VMD-PE-CNN模型的预测误差
在训练数据和测试数据上VMD-PE-CNN模型预测值与实测值之间的均方根误差分别为0.073 5和0.111 3,CNN模型为0.223 9和0.291 3,LSTM模型为0.281 9和0.322 2。较之后两者,VMD-PE-CNN模型在训练集上的误差分别降低67.2%和73.9%,在测试集上分别降低61.8%和65.5%。说明通过变分模态分解能够更加充分地挖掘数据中的趋势性和周期性规律,从而大幅降低预测误差,提高模型预测能力。图8和图9分别给出了VMD-PE-CNN、CNN和LSTM三种模型在训练集和测试集上的预测曲线及其与实测曲线的相互比较。可以看出,在训练集上三种模型的预测值与实测值吻合程度均较高,但是在测试集上本文提出的VMD-PE-CNN模型的预测值与实测值最为吻合,说明本文模型具有更强的泛化能力。表2给出了三种模型在训练集和测试集上部分典型日期的实测值与预测值,这些日期分布在不同的时间段,测值具有不同的符号和绝对值大小。从表2可以看出:与CNN和LSTM模型相比,VMD-PE-CNN模型具有更高的预测精度,特别是对于绝对数值较小的测值仍然表现出良好的预测性能。


图8 VMD-PE-CNN、CNN和LSTM模型在训练集上的预测曲线

图9 VMD-PE-CNN、CNN和LSTM模型在测试集上的预测曲线
3 结果讨论
从工程实例分析可以看出,VMD-PE-CNN模型与单纯的CNN和LSTM模型相比具有更强的预测能力,不管是在训练数据上,还是测试数据上,预测精度都得到大幅提高,特别是在测试数据上表现出更强的泛化性能。一方面是由于模型采用了VMD将原始变形监测数据进行模态分解后对具有不同尺度特征的模态分量分别建模,从而能够充分挖掘数据中多尺度特征;另一方面的原因是模型通过计算分解余量的PE确定最优模态分量数,减少了模型中的主观因素,降低了信息缺失和噪声的影响。
VMD-PE-CNN模型由于是对原始数据的多个模态分量序列分别进行CNN建模,因此模型的计算量较之单纯的CNN要有所增大,特别是当数据量很大的时候,这种计算量的增大会导致计算时间大幅增加,因此需要进一步提高模型的计算效率。此外,模型直接对单测点变形监测数据进行建模预测,没有考虑变形与荷载和环境影响因素之间的关系以及测点的空间位置特征,其物理意义不够清晰,因此需要进一步研究模型物理意义的可解释性以及考虑时空因素的预测模型。
4 结 论
本文构建了一种基于VMD-PE-CNN的混凝土坝变形预测模型,通过VMD将实测变形监测数据分解为一系列模态分量,根据分解余量的排列熵确定模态分量的最优个数,利用CNN对每个模态分量建立预测子模型,并通过网格搜索法确定CNN的较优网络结构和参数组合,最后将各个分支预测值叠加重构得到最终的大坝变形预测值。通过工程实例计算分析,得到以下结论:
(1)采用计算模态分解余量排列熵的方法可以获取最优的模态分量数,进而可以通过变分模态分解更好地挖掘监测数据中的特征和信息,降低预测难度。
(2)较之于CNN和LSTM模型,VMD-PE-CNN模型能够更好地提取数据特征,从而使得其具有更高的预测精度和更强的泛化性能。
本文目前仅研究了单测点变形预测,未来还需要进一步研究模型在混凝土坝多点、多步变形预测中的应用,以及模型物理意义的可解释性。
水利水电技术(中英文)
水利部《水利水电技术(中英文)》杂志是中国水利水电行业的综合性技术期刊(月刊),为全国中文核心期刊,面向国内外公开发行。本刊以介绍我国水资源的开发、利用、治理、配置、节约和保护,以及水利水电工程的勘测、设计、施工、运行管理和科学研究等方面的技术经验为主,同时也报道国外的先进技术。期刊主要栏目有:水文水资源、水工建筑、工程施工、工程基础、水力学、机电技术、泥沙研究、水环境与水生态、运行管理、试验研究、工程地质、金属结构、水利经济、水利规划、防汛抗旱、建设管理、新能源、城市水利、农村水利、水土保持、水库移民、水利现代化、国际水利等。

[注:本文部分图片来自互联网!未经授权,不得转载!每天跟着我们读更多的书]
互推传媒文章转载自第三方或本站原创生产,如需转载,请联系版权方授权,如有内容如侵犯了你的权益,请联系我们进行删除!
如若转载,请注明出处:http://www.hfwlcm.com/info/300352.html
相关文章
-

-

能天使是00高达系列中人气最高的机体之一,深受很多模友的喜欢。如果把变形概念加入能天使高达模型上会变成什么样呢?接下来为大家带来的是模友ティエリア姉貴的可变形跑车能天
-

变形金刚狂派霸天虎飞天虎狂派霸天虎飞虎队组合成为飞天虎,由超级运载卡车汽车大师以及其他四部超级跑车组合而成,最初登场来自变形金刚G1动画片,是狂派霸天虎的地面快速行动
-

佛劳洛斯因为使用了巴巴托斯高达模型的骨架也有色的可塑性,被模友们改造成各种动漫IP中的角色,改造之后的作品很多都是佳作!如果把佛劳洛斯高达模型改造成数码宝贝中的角色会
-

很多模友疑问可以变成狮子的里昂高达模型都是由什么机甲周边模型混搭改造的呢?它是怎样从高达变成狮子呢?接下来为大家带来的是Gp_oyaman的狮子里昂高达模型,搭配数量整理和变
-

将高达模型做成变形玩具,这是作者的最新研制成果,其实已经是第二代作品了。上一次我们只介绍了元祖与钢坦克的合体变形,然而初代三小强怎能少了钢加农!主要的合体思路是以
-

-

天蚀高达是高达seed外传中的主角机,可以搭载各种外挂装备,还可以变形,算是今年模友们比较期待的MG比例高达模型。虽然这款高达模型还没有出,但是已经有手艺好的模友制作了H